Usage
Grimp provides an API in the form of an ImportGraph that represents all the imports within one or more
top-level Python packages. This object has various methods that make it easy to find out information about
the packages’ structures and interdependencies.
Terminology
The terminology around Python packages and modules can be a little confusing. Here are the definitions we use, taken in part from the official Python docs:
Module: A file containing Python definitions and statements. This includes ordinary
.pyfiles and__init__.pyfiles.Package: A Python module which can contain submodules or recursively, subpackages.
Top Level Package: A package that is not a subpackage of another package.
Graph: A graph in the mathematical sense of a collection of items with relationships between them. Grimp’s
ImportGraphis a directed graph of imports between modules.Direct Import: An import from one module to another.
Import Chain: A chain of direct imports between two modules, possibly via other modules. For example, if
mypackage.fooimportsmypackage.bar, which in turn importsmypackage.baz, then there is an import chain betweenmypackage.fooandmypackage.baz.Squashed Module: A module in the graph that represents both itself and all its descendants. Squashed modules allow parts of the graph to be simplified. For example, if you include external packages when building the graph, each external package will exist in the graph as a single squashed module.
Building the graph
import grimp
# Single package
graph = grimp.build_graph('mypackage')
# Multiple packages
graph = grimp.build_graph('mypackage', 'anotherpackage', 'onemore')
# Include imports of external packages
graph = grimp.build_graph('mypackage', include_external_packages=True)
# Exclude imports within a TYPE_CHECKING guard
graph = grimp.build_graph('mypackage', exclude_type_checking_imports=True)
# Use a different cache directory, or disable caching altogether
graph = grimp.build_graph('mypackage', cache_dir="/path/to/cache")
graph = grimp.build_graph('mypackage', cache_dir=None)
- grimp.build_graph(package_name, *additional_package_names, include_external_packages=False, exclude_type_checking_imports=False)
Build and return an ImportGraph for the supplied package or packages.
- Parameters:
package_name (str) – The name of an importable package, for example
'mypackage'. For regular packages, this must be the top level package (i.e. one with no dots in its name). In the special case of namespace packages, the name of the portion may be supplied instead, for example'mynamespace.foo'. If the portion is supplied, its ancestor packages will not be included in the graph.additional_package_names (tuple[str, ...]) – Tuple of any additional package names. These can be supplied as positional arguments, as in the example above.
include_external_packages (bool, optional) –
Whether to include external packages in the import graph. If this is
True, any other top level packages (including packages in the standard library) that are imported by this package will be included in the graph as squashed modules (see Terminology above).The behaviour is more complex if one of the specified packages is a namespace portion. In this case, the squashed module will have the shallowest name that doesn’t clash with any internal modules. For example, in a graph with internal packages
namespace.fooandnamespace.bar.one.green,namespace.bar.one.orange.alphawould be added to the graph asnamespace.bar.one.orange. However, in a graph with onlynamespace.foopassed, the same external module would be added asnamespace.bar.Note: external packages are only analysed as modules that are imported; any imports they make themselves will not be included in the graph.
exclude_type_checking_imports (bool, optional) – Whether to exclude imports made in type checking guards. If this is
True, any import made under anif TYPE_CHECKING:statement will not be added to the graph. See the typing module documentation for reference. (The type checking guard is detected purely by looking for a statement in the formif TYPE_CHECKINGorif {some_alias}.TYPE_CHECKING. It does not check whetherTYPE_CHECKINGis actually the attribute from thetypingmodule.)cache_dir (str, optional) – The directory to use for caching the graph. Defaults to
.grimp_cache. To disable caching, passNone. See Caching.
- Returns:
An import graph that you can use to analyse the package.
- Return type:
ImportGraph
Methods for analysing the module tree
- ImportGraph.modules
All the modules contained in the graph.
- return:
Set of module names.
- rtype:
A set of strings.
- ImportGraph.find_children(module)
Return all the immediate children of the module, i.e. the modules that have a dotted module name that is one level below.
- param str module:
The importable name of a module in the graph, e.g.
'mypackage'or'mypackage.foo.one'. This may be any non-squashed module. It doesn’t need to be a package itself, though if it isn’t, it will have no children.- return:
Set of module names.
- rtype:
A set of strings.
- raises:
ValueErrorif the module is a squashed module, as by definition it represents both itself and all of its descendants.
- ImportGraph.find_descendants(module)
Return all the descendants of the module, i.e. the modules that have a dotted module name that is below the supplied module, to any depth.
- param str module:
The importable name of the module, e.g.
'mypackage'or'mypackage.foo.one'. As withfind_children, this doesn’t have to be a package, though if it isn’t then the set will be empty.- return:
Set of module names.
- rtype:
A set of strings.
- raises:
ValueErrorif the module is a squashed module, as by definition it represents both itself and all of its descendants.
- ImportGraph.find_matching_modules(expression)
Find all modules matching the passed expression (see Module expressions).
- Parameters:
expression (str) – A module expression used for matching.
- Returns:
A set of module names matching the expression.
- Return type:
A set of strings.
- Raises:
grimp.exceptions.InvalidModuleExpressionif the module expression is invalid.
Methods for analysing direct imports
- ImportGraph.direct_import_exists(importer, imported, as_packages=False)
- Parameters:
importer (str) – A module name.
imported (str) – A module name.
as_packages (bool) – Whether or not to treat the supplied modules as individual modules, or as entire packages (including any descendants).
- Returns:
Whether or not the importer directly imports the imported module.
- Return type:
TrueorFalse.
- ImportGraph.find_modules_directly_imported_by(module)
- Parameters:
module (str) – A module name.
- Returns:
Set of all modules in the graph are imported by the supplied module.
- Return type:
A set of strings.
- ImportGraph.find_modules_that_directly_import(module)
- Parameters:
module (str) – A module name.
- Returns:
Set of all modules in the graph that directly import the supplied module.
- Return type:
A set of strings.
- ImportGraph.get_import_details(importer, imported)
Provides a way of seeing any available metadata about direct imports between two modules. Usually the list will consist of a single dictionary, but it is possible for a module to import another module more than once.
This method should not be used to determine whether an import is present: some of the imports in the graph may have no available metadata. For example, if an import has been added by the
add_importmethod without theline_numberandline_contentsspecified, then calling this method on the import will return an empty list. If you want to know whether the import is present, usedirect_import_exists.The details returned are in the following form:
[ { 'importer': 'mypackage.importer', 'imported': 'mypackage.imported', 'line_number': 5, 'line_contents': 'from mypackage import imported', }, # (additional imports here) ]
If no such import exists, or if there are no available details, an empty list will be returned.
- Parameters:
importer (str) – A module name.
imported (str) – A module name.
- Returns:
A list of any available metadata for imports between two modules.
- Return type:
List of dictionaries with the structure shown above. If you want to use type annotations, you may use the
grimp.DetailedImportTypedDict for each dictionary.
- ImportGraph.count_imports()
- Returns:
The number of imports in the graph. For backward compatibility reasons,
count_importsdoes not actually return the number of imports, but the number of dependencies between modules. So if a module is imported twice from the same module, it will only be counted once.- Return type:
Integer.
- ImportGraph.find_matching_direct_imports(import_expression)
Find all direct imports matching the passed import expression.
The imports returned are in the following form:
[ { 'importer': 'mypackage.importer', 'imported': 'mypackage.imported', }, # (additional imports here) ]
- Parameters:
import_expression (str) – An expression in the form
"importer_expression -> imported_expression", where each expression is a module expression (see Module expressions). Example:"mypackage.*.blue -> mypackage.*.green".- Returns:
An ordered list of direct imports matching the expressions (ordered alphabetically).
- Return type:
List of dictionaries with the structure shown above. If you want to use type annotations, you may use the
grimp.ImportTypedDict for each dictionary.- Raises:
grimp.exceptions.InvalidImportExpressionif the expression is not well-formed.
Methods for analysing import chains
- ImportGraph.find_downstream_modules(module, as_package=False)
- Parameters:
module (str) – A module name.
as_package (bool) – Whether or not to treat the supplied module as an individual module, or as an entire package (including any descendants). If treating it as a package, the result will include downstream modules external to the supplied module, and won’t include modules within it.
- Returns:
All the modules that import (even indirectly) the supplied module.
- Return type:
A set of strings.
Examples:
# Returns the modules downstream of mypackage.foo. graph.find_downstream_modules('mypackage.foo') # Returns the modules downstream of mypackage.foo, mypackage.foo.one and # mypackage.foo.two. graph.find_downstream_modules('mypackage.foo', as_package=True)
- ImportGraph.find_upstream_modules(module, as_package=False)
- Parameters:
module (str) – A module name.
as_package (bool) – Whether or not to treat the supplied module as an individual module, or as a package (i.e. including any descendants, if there are any). If treating it as a subpackage, the result will include upstream modules external to the package, and won’t include modules within it.
- Returns:
All the modules that are imported (even indirectly) by the supplied module.
- Return type:
A set of strings.
- ImportGraph.find_shortest_chain(importer, imported, as_packages=False)
- Parameters:
importer (str) – The module at the start of a potential chain of imports between
importerandimported(i.e. the module that potentially importsimported, even indirectly).imported (str) – The module at the end of the potential chain of imports.
as_packages (bool) – Whether to treat the supplied modules as individual modules, or as packages (including any descendants, if there are any). If treating them as packages, all descendants of
importerandimportedwill be checked too.
- Returns:
The shortest chain of imports between the supplied modules, or None if no chain exists.
- Return type:
A tuple of strings, ordered from importer to imported modules, or None.
- ImportGraph.find_shortest_chains(importer, imported, as_packages=True)
- Parameters:
importer (str) – A module or subpackage within the graph.
imported (str) – Another module or subpackage within the graph.
as_packages (bool) – Whether or not to treat the imported and importer as an individual module, or as a package (including any descendants, if there are any). If treating them as packages, all descendants of
importerandimportedwill be checked too. Defaults to True.
- Returns:
The shortest import chains that exist between the
importerandimported, and between any modules contained within them. Only one chain per upstream/downstream pair will be included. Any chains that are contained within other chains in the result set will be excluded.- Return type:
A set of tuples of strings. Each tuple is ordered from importer to imported modules.
- ImportGraph.chain_exists(importer, imported, as_packages=False)
- Parameters:
importer (str) – The module at the start of the potential chain of imports (as in
find_shortest_chain).imported (str) – The module at the end of the potential chain of imports (as in
find_shortest_chain).as_packages (bool) – Whether to treat the supplied modules as individual modules, or as packages (including any descendants, if there are any). If treating them as packages, all descendants of
importerandimportedwill be checked too.
- Returns:
Return whether any chain of imports exists between
importerandimported, even indirectly; in other words, doesimporterdepend onimported?- Return type:
bool
Higher level analysis
- ImportGraph.find_illegal_dependencies_for_layers(layers, containers=None)
Find dependencies that don’t conform to the supplied layered architecture.
- Parameters:
layers (Sequence[Layer | str | set[str]]) – A sequence of layers ordered from the highest to the lowest. The module names passed are relative to any containers passed in: for example, to specify
mypackage.foo, you could either pass it in directly, or passmypackageas the container (see thecontainersargument) andfooas the module name. A layer may optionally consist of multiple module names. If it does, the layer will by default treat each module as ‘independent’ (see below), though this can be overridden by passingindependent=Falsewhen instantiating theLayer. For convenience, if a layer consists only of one module name then a string may be passed in place of theLayerobject. Additionally, if the layer consists of multiple independent modules, that can be passed as a set of strings instead of aLayerobject. A closed layer may be created by passingclosed=Trueto prevent higher layers from importing directly from layers below the closed layer (see Closed layers section below). Any modules specified that don’t exist in the graph will be silently ignored.containers (set[str]) – The parent modules of the layers, as absolute names that you could import, such as
mypackage.foo. (Optional.)
- Returns:
The illegal dependencies in the form of a set of
PackageDependencyobjects. Each package dependency is for a different permutation of two layers for which there is a violation, and contains information about the illegal chains of imports from the lower layer (the ‘importer’) to the higher layer (the ‘imported’).- Return type:
set[PackageDependency].- Raises:
grimp.exceptions.NoSuchContainer – if a container is not a module in the graph.
Overview
‘Layers’ is a software architecture pattern in which a list of modules/packages have a dependency direction from high to low. In other words, a higher layer would be allowed to import a lower layer, but not the other way around.

In this diagram,
mypackagehas a layered architecture in which the subpackagedis the highest layer and the subpackageais the lowest layer.awould not be allowed to import from any of the modules above it, whiledcan import from everything. In the middle,ccould import fromaandb, but notd.These layers can be individual
.pymodules or subpackages; if they’re subpackages then the architecture is enforced for all modules within the subpackage, somypackage.a.onewould not be allowed to import frommypackage.b.two.Here’s how the architecture shown can be checked using Grimp:
dependencies = graph.find_illegal_dependencies_for_layers( layers=( "mypackage.d", "mypackage.c", "mypackage.b", "mypackage.a", ), )
Containers
Containers allow for a less repetitive way of specifying layers, and are particularly useful if you want to specify a recurring pattern of layers in different places in the graph.
Example with containers:
dependencies = graph.find_illegal_dependencies_for_layers( layers=( "high", "medium", "low", ), containers={ "mypackage.foo", "mypackage.bar", }, )
This call will check that, for example,
mypackage.foo.lowdoesn’t import frommypackage.foo.medium. There is no checking between the containers, though, somypackage.foo.lowwould be able to importmypackage.bar.high.Layers containing multiple siblings
Grimp supports the presence of multiple sibling modules or packages within the same layer. In the diagram below, the modules
blueandgreenare ‘independent’ in the same layer, meaning that, in addition to not being allowed to import from layers above them, they are not allowed to import from each other.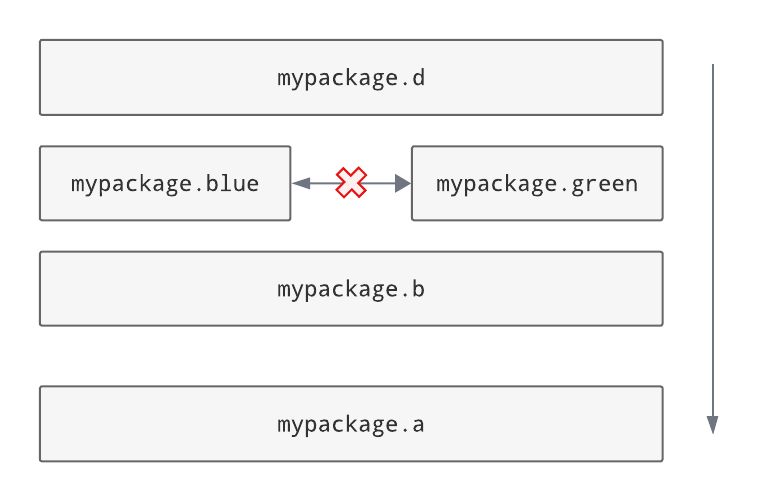
An architecture like this can be checked by passing a
setof module names:dependencies = graph.find_illegal_dependencies_for_layers( layers=( "mypackage.d", {"mypackage.blue", "mypackage.green"}, "mypackage.b", "mypackage.a", ), )
Alternatively, siblings can be designated as non-independent, meaning that they are allowed to import from each other, as shown:
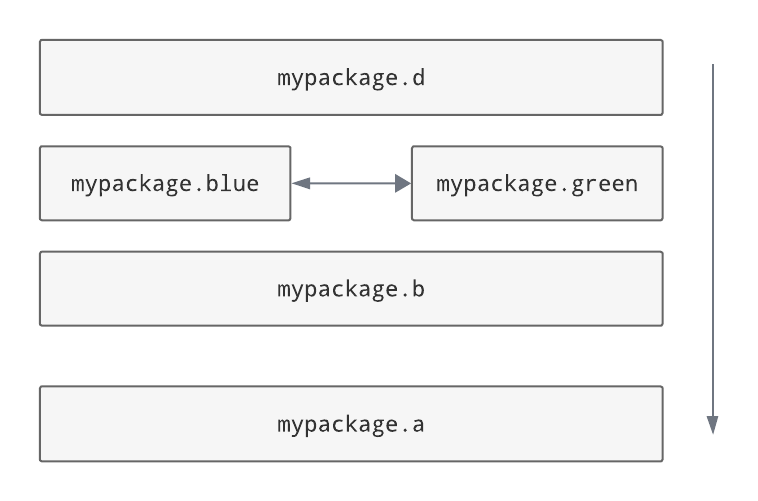
To check this architecture, use the
grimp.Layerclass, specifying that the modules are not independent:dependencies = graph.find_illegal_dependencies_for_layers( layers=( "mypackage.d", grimp.Layer("mypackage.blue", "mypackage.green", independent=False), "mypackage.b", "mypackage.a", ), )
Closed layers
A closed layer may be created by passing
closed=True. Closed layers provide an additional constraint in your architecture that prevents higher layers from “reaching through” to access lower layers directly. Imports from higher to lower layers cannot bypass closed layers - the closed layer must be included in the import chain.This is particularly useful for enforcing architectural boundaries where you want to hide implementation details of lower layers and ensure that higher layers only interact with the public interface provided by the closed layer.
Return value
The method returns a set of
PackageDependencyobjects that describe different illegal imports.Note: each returned
PackageDependencydoes not include all possible illegalRouteobjects. Instead, once an illegalRouteis found, the algorithm will temporarily remove it from the graph before continuing with its search. As a result, any illegal Routes that have sections in common with other illegal Routes may not be returned.Unfortunately the Routes included in the PackageDependencies are not, currently, completely deterministic. If there are multiple illegal Routes of the same length, it is not predictable which one will be found first. This means that the PackageDependencies returned can vary for the same graph.
- class Layer
A layer within a layered architecture.
- module_tails
set[str]: A set, each element of which is the final component of a module name. This ‘tail’ is combined with any container names to provide the full module name. For example, if a container is"mypackage"then to refer to"mypackage.foo"you would supply"foo"as the module tail.- independent
bool: Whether the sibling modules within this layer are required to be independent.
- class PackageDependency
A collection of import dependencies from one Python package to another.
- importer
str: The full name of the package within which all the routes start; the downstream package. E.g. “mypackage.foo”.- imported
str: The full name of the package within which all the routes end; the upstream package. E.g. “mypackage.bar”.- routes
frozenset[grimp.Route]: A set ofRouteobjects from importer to imported.
- class Route
A set of import chains that share the same middle.
The route fans in at the head and out at the tail, but the middle of the chain just links individual modules.
Example: the following Route represents a chain of imports from
mypackage.orange -> mypackage.utils -> mypackage.helpers -> mypackage.green, plus an import frommypackage.redtomypackage.utils, and an import frommypackage.helperstomypackage.blue:Route( heads=frozenset( { "mypackage.orange", "mypackage.red", } ), middle=( "mypackage.utils", "mypackage.helpers", ), tails=frozenset( { "mypackage.green", "mypackage.blue", } ), )
- heads
frozenset[str]: The importer modules at the start of the chain.
- middle
tuple[str]: A sequence of imports that link the head modules to the tail modules.
- tails
frozenset[str]: Imported modules at the end of the chain.
- ImportGraph.nominate_cycle_breakers(package)
Choose an approximately minimal set of dependencies that, if removed, would make the package locally acyclic.
‘Acyclic’ means that there are no direct dependency cycles between the package’s children. Indirect dependencies (i.e. ones involving modules outside the supplied package) are disregarded, as are imports between the package and its children.
‘Dependency cycles’ mean cycles between the squashed children (see Terminology above).
Multiple sets of cycle breakers can exist for a given package. To arrive at this particular set, the following approach is used:
Create a graph whose nodes are each child of the package.
For each pair of children, add directed edges corresponding to whether there are imports between those two children (as packages, rather than individual modules). The edges are weighted according to the number of dependencies they represent: this is usually the same as the number of imports, but if a module imports another module in multiple places, it will be treated as a single dependency.
Calculate the approximate minimum weighted feedback arc set. This attempts to find a set of edges with the smallest total weight that can be removed from the graph in order to make it acyclic. It uses the greedy cycle-breaking heuristic of Eades, Lin and Smyth: not guaranteed to find the optimal solution, but it is relatively fast.
These edges are then used to look up all the concrete imports in the fully unsquashed graph, which are returned. For example, an edge discovered in step 3. of
mypackage.foo -> mypackage.bar, with a weight 3, might correspond to these three imports:mypackage.foo.blue -> mypackage.bar.green,mypackage.foo.blue.one -> mypackage.bar.green.two, andmypackage.foo.blue -> mypackage.bar.green.three.
- Parameters:
package (str) – The package in the graph to check for cycles. If a module with no children is passed, an empty set is returned.
- Returns:
A set of imports that, if removed, would make the imports between the the children of the supplied package acyclic.
- Return type:
set[tuple[str, str]]. In each import tuple, the first element is the importer module and the second is the imported.
Methods for manipulating the graph
- ImportGraph.add_module(module, is_squashed=False)
Add a module to the graph.
- Parameters:
module (str) – The name of a module, for example
'mypackage.foo'.is_squashed (bool) – If True, the module should be treated as a ‘squashed module’ (see Terminology above).
- Returns:
None
- ImportGraph.remove_module(module)
Remove a module from the graph.
If the module is not present in the graph, no exception will be raised.
- Parameters:
module (str) – The name of a module, for example
'mypackage.foo'.- Returns:
None
- ImportGraph.add_import(importer, imported, line_number=None, line_contents=None)
Add a direct import between two modules to the graph. If the modules are not already present, they will be added to the graph.
- Parameters:
importer (str) – The name of the module that is importing the other module.
imported (str) – The name of the module being imported.
line_number (int) – The line number of the import statement in the module.
line_contents (str) – The line that contains the import statement.
- Returns:
None
- ImportGraph.remove_import(importer, imported)
Remove a direct import between two modules. Does not remove the modules themselves.
- Parameters:
importer (str) – The name of the module that is importing the other module.
imported (str) – The name of the module being imported.
- Returns:
None
- ImportGraph.squash_module(module)
‘Squash’ a module in the graph (see Terminology above).
Squashing a pre-existing module will cause all imports to and from the descendants of that module to instead point directly at the module being squashed. The import details (i.e. line numbers and contents) will be lost for those imports. The descendants will then be removed from the graph.
- Parameters:
module (str) – The name of a module, for example
'mypackage.foo'.- Returns:
None
- ImportGraph.is_module_squashed(module)
Return whether a module present in the graph is ‘squashed’ (see Terminology above).
- Parameters:
module (str) – The name of a module, for example
'mypackage.foo'.- Returns:
bool
Module expressions
A module expression is used to refer to sets of modules.
*stands in for a module name, without including subpackages.
**includes subpackages too.Examples:
mypackage.foo: matchesmypackage.fooexactly.
mypackage.*: matchesmypackage.foobut notmypackage.foo.bar.
mypackage.*.baz: matchesmypackage.foo.bazbut notmypackage.foo.bar.baz.
mypackage.*.*: matchesmypackage.foo.barandmypackage.foobar.baz.
mypackage.**: matchesmypackage.foo.barandmypackage.foo.bar.baz.
mypackage.**.qux: matchesmypackage.foo.bar.quxandmypackage.foo.bar.baz.qux.
mypackage.foo*: is not a valid expression. (The wildcard must replace a whole module name.)